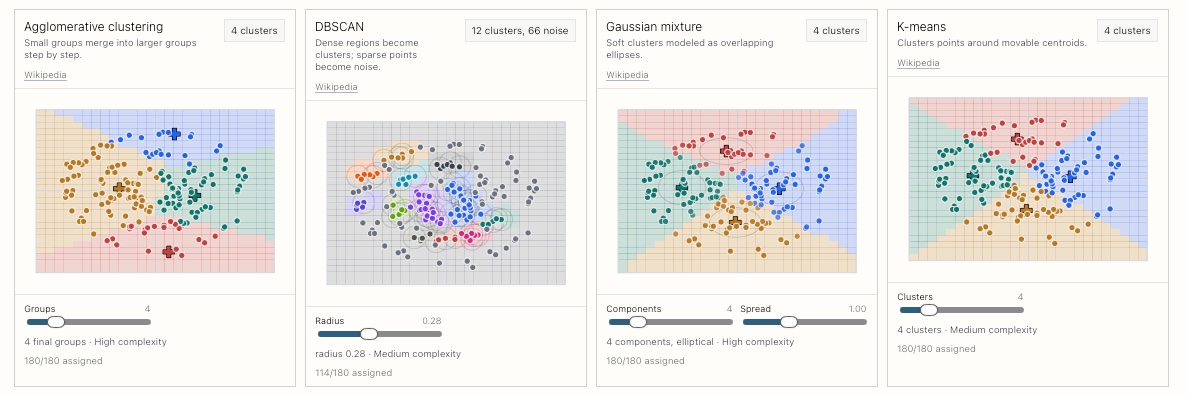
The other day, I was tinkering with model parameters and second-guessing myself. I wondered, wouldn’t it be cool if i could compare side by side the results of different models? Yeah, it would. I ended up building a small interactive explainer for seeing how different classification and clustering approaches behave on the same two-dimensional data.… Continue reading Classification, visualized
Software Dev.
Software development articles by Daniel Pradilla on programming, Python, AWS, AI, and practical engineering work.
mambo-rescue

Rescuing an old website without turning it into a life project A few days ago, I finally got around to something I’d been putting off since about 2012: cleaning up a mess on one of my old websites. One part is still plain HTML. Another runs on WordPress. And in the middle, for a few… Continue reading mambo-rescue
Flipasio

My eldest daughter recently discovered the classic LCD calculator trick: type certain numbers, flip it, and make it spell words. She was thrilled to show me, and I was just as excited watching her find that little “useless” easter egg that entertained me during way too many hours in classes that I should’ve paid more… Continue reading Flipasio
EchoTree

For years now I kept some of my social accounts alive with a Python script. It read from a collection of RSS feeds and shared at random times. It worked, my feeds stayed active, and people asked me what was I doing reading at 3am. The script had a bit of personality: it logged out… Continue reading EchoTree
5 lessons I learned playing with Clawdbot, a local agentic assistant

I’ve spent the last few weeks playing with Clawdbot. My instance is named Clawd. If you haven’t seen this category yet: think “chat assistant”, but with hands. It can run commands, write files, poke your integrations, and generally do the annoying glue-work you normally do by tab-switching and copy/pasting. TL;DR Clawdbot lets you go from… Continue reading 5 lessons I learned playing with Clawdbot, a local agentic assistant