
Imagine you could estimate how hard would be to read a document, before reading it. Imagine you could do it for entire batches of documents you need to process. Imagine you could have a recommender system that would help you prioritize unread documents according to their difficulty.
A bit of experimentation with the public United Nations Parallel Corpus taught me about readability scoring, parsing sentences in XML, UN organ classification, interactive charts, and gave me some ideas for future fun personal projects. It also revealed that you need to have graduate-level education to understand a UN document, that the readability of UN documents stabilized around 2011, and that the traditional readability scoring formulae might not be enough to score documents at this level.
Get the code at https://github.com/danielpradilla/python-readability
A bit of background
According to online sources, the Department for General Assembly and Conference Management of the United Nations translates around 200 documents per day into the six official United Nations languages. It is, effectively, a big document factory and a rich source for natural language processing enthusiasts. Since 2016, an official corpus has been publicly available, containing almost 800 thousand documents, spanning 25 years, from 1990 to 2014.
I wonder how long did it take to process each one of these documents. Surely some of them must have taken more time than others. I imagine that long documents, for example, would demand translators to hold their concentration on the background of the text for long periods of time. On the other hand, short, highly technical documents, might be equally difficult to translate. Document length might not correlate neatly to translation time. United Nations parliamentary documents are inherently linked to meetings, and this introduces additional human factors which affect translation time: document priority, unexpected delays, interruptions and holidays. Additionally, some documents might be drafted by people whose native tongue is not one of the 6 official languages of the UN (Arabic, Chinese, English, French, Russian or Spanish).
Translation is a process of transferring meaning and high-quality translations require understanding the text. If we could measure how easy is to read a text, we could infer –perhaps– the comparative difficulty of translating two documents of similar length. The subject matter might also have some influence, General Assembly resolutions might be an easier read than highly technical documents on trade. Readability scoring could provide some insight into the difficulty of translating a text.
The first time I brushed this subject was back in 2010-11 when I worked as a freelance translator for a car industry website at the height of the SEO craze. Some WordPress plugins rated posts according to their keyword usage and sentence length, and I had to meet certain “readability” target before clicking “publish”.
Then, in 2014, I developed a small windows app (and companion Class) for counting the words in a batch of Word documents. Silly me, I thought that it would be relatively easy because a word is any group of characters separated by a space or punctuation right? I soon discovered that I was wrong, I was getting around 5 to 10% deviation from MS Word, and I wasn’t even thinking about Chinese script! So I ended up piggybacking on the MS Word counting feature –the class relies on some calls to the Word API to force a count using criteria set by very clever people at Microsoft.
A couple of years later, I revisited the subject and thought that it would be cool that, apart from counting the words, this class could be enhanced to assess document readability. I started experimenting with the Flesch-Kincaid readability score and got some crazy results (like a 10-year old would be able to understand some of these texts, or you needed to be 99 years for some others). I thought I would need a larger or, at least different, data set.
It wasn’t until the end of 2017 when I first ventured into NLP and found the public UN Corpus, that I thought to give another try to readability scoring.
My long-term goal of this exercise would be to implement a recommender system that utilizes a model of text difficulty for estimating the challenges within a document batch, and suggests the best course of action when faced with seemly similar texts. A person could take the output of the recommender system and make an informed decision considering other human factors.
If document distributors were to know in advance which upcoming documents would be harder to translate, they could properly assign the more experienced translators to those documents, and plan for more time-consuming revision work.
Parsing the UN corpus
I downloaded the corpus from https://conferences.unite.un.org/UNCorpus. That was in September 2018 and I recently discovered that they’ve changed that web page and the corpus seems to have disappeared. Let me know if you find it. In order to feed it to the readability scorer, I had to extract the body of the document. The documents are stored in XML. 159,323 XML files to be precise. I thought about going with BeautifulSoup, which is what I normally use for parsing markup text, but ended up using python’s ElementTree XML, which is pretty fast and complete.
Once you open each file, you can then extract the root of the XML and loop through the different paragraphs and sentences.
tree = get_xml_tree(path)
for paragraph in tree.findall(".//body/p"):
for sentence in paragraph.findall("s"):
if sentence.text is not None:
body += sentence.text
I took the opportunity also to extract some other metadata contained in the document, like the symbol (unique identifier) and publication date.
Readability scoring with python
One of the aspects that I like about the readability scoring is that is length-agnostic. Most of the readability formulae are based on the percentage of “complicated” multi-syllable words used in the text.
Right off the bat, I found two potential problems with this approach: all these formulae were developed for English, so the scales of the outcomes are only meaningful for English texts. Fortunately, the UN corpus I was working on was also English-only. The second problem was that the majority of the formulae seem fine-tuned to measure reading comprehension for primary education (it becomes pretty obvious when you see the grading scales). Not necessarily what you are looking for in texts aimed for adults. Let’s ignore these two things for a moment and move on.
I found a readability scoring python library by Wim Muskee, whose DNA can be traced back to the Python Natural Language Toolkit. That’s always a good sign. As mentioned above, not every word is a word and –ultimately– if you are scoring based on word and sentence length, you need a very good counter.
Choosing readability formula
The python library that I found offers calculations for the following:
- Flesch-Kinkaid: Very popular upgrade of the Flesch Reading Ease. Correlates 0.91 with comprehension.
- Coleman-Liau: counts the number of characters instead of the number of words.
- Dale-Chall: needs a list of 3000 “easy” words. It correlates 0.93 with comprehension and seems to be the most widely used in scientific research.
- Linsear Write: assigns an arbitrary value to “hard” and “easy” word. I figured that if I was to go down that path, I might as well rely on Dale-Chall.
- SMOG: is mostly used in healthcare, so I discarded it.
- Automated readability test: counts the number of characters instead of the number of words.
I had to choose one. Really? Why not all of them? Through the magic of multiprocessing, I was able to score the corpus after an hour.
I got the “easy” words for Dale-Chall from http://countwordsworth.com/blog/dale-chall-easy-word-list-text-file/. If you want a txt file already properly lowercased, I have one for you.
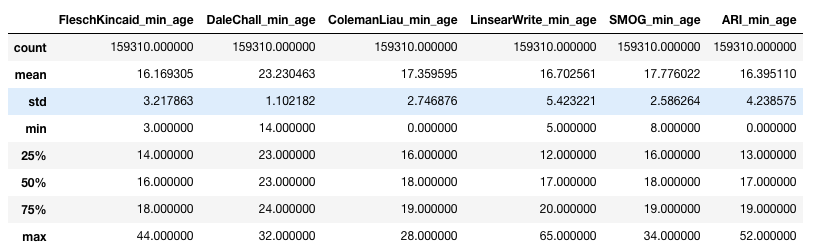
The library also offers a handy score-to-minimum-age conversion, which ends up providing the minimum age a potential reader needs to be to understand the text.
Analyzing the distribution of minimum age for the different methods, the distribution of Dale-Chall seems more precise. Flesch-Kincaid seems to be too spread out, and the rest I honestly don’t believe that some of these documents can be understood by a 5 or a 10-year-old.
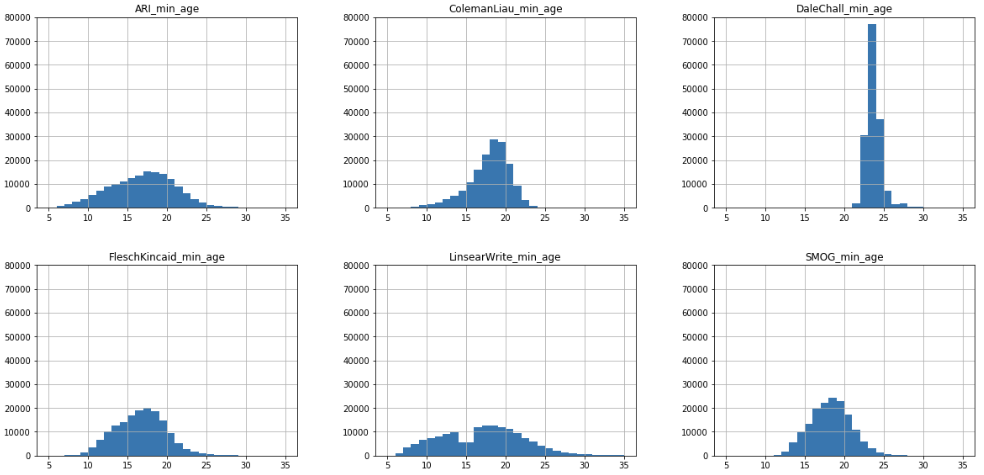
A word is not a word. A sentence is not a sentence
I noticed that there were some documents which were reporting a minimum age of 700 years for Flesch-Kinkaid. And as boring or technical as some of these documents might be, I doubt they would require a lawyer from the middle ages to understand. I found out that if a paragraph ended in coma or semi-colon, it was joined with the next paragraph by the NLTK sentence parser. This resulted in very long, seemly-rambling paragraphs that threw off the scoring. The problem was particularly acute in documents which contained long enumerations, like A/RES/56/173 Note that many paragraphs end in a comma or semicolon:

I also found that many lists items do not end with a period, and they were parsed as a single long-winded sentence. I ended up testing for punctuation at the end of sentences and adding a period when I couldn’t find any punctuation.
Extracting the organs
One of the things I want to know if there is some sort of relationship between the United Nations Organ who submitted the text and its reading difficulty. Are Human Rights documents easier to read than Conference of Disarmament ones?
Organ and organ subsidiary information can be extracted from the symbol of the document. The symbol is the UN standard for uniquely identifying a document. This page has a good explanation, and this official UN document contains a good summary of the main symbols.
From this explanation, you could derive an approximate classification of organs. After a lot of wikipediaing, I ended up with a list of 63 entries that looks like this:
| Symbol Root | Organ |
|---|---|
| A-HRC | Human Rights Council |
| A | General Assembly |
| ECE | UNECE |
| TRADE | UNECE |
and so on
Here you can download the latest version of my symbol-organ correlation.
Analysis of the scoring
A box plot of the minimum age grouped by organs reveals that, with Dale-Chall formula, the majority of the scores fluctuate between 23 and 24 years old. Graduate-level education. This intuitively makes sense. However, I was disappointed when I made a box plot of the classification and saw how little differences could be observed between organs. In hindsight, this was kind of expected, as the standard deviation for the Dale-Chall score in the full dataset is close to 1.
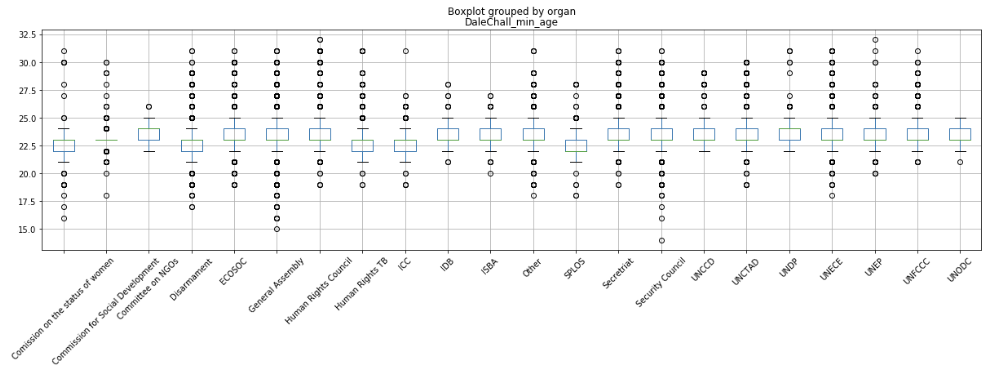
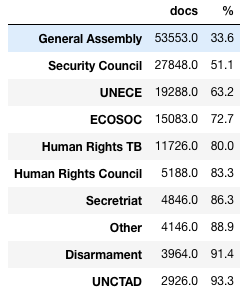
These scores might be affected by sparse data. A top-10 list of organs by the number of documents, covers around 90% of the document count and get an even less exciting result.

This interactive chart highlights the outliers as extra dots outside of the box plots. On hover, you may see the symbol this dot is related to. Feel free to plug this into the UN’s Official Document System and find out why.
Flesch-Kinkaid has some interesting variance. But who am I trying to cheat? Dale-Chall seems more trustworthy and makes more sense.
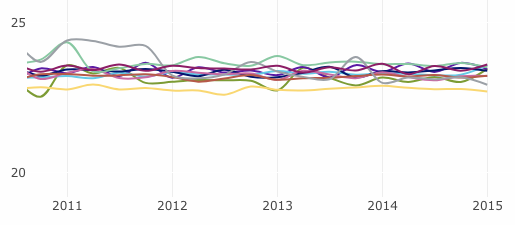
Change in difficulty year-over-year
A plot of mean minimum age per date seems a little hard to digest.
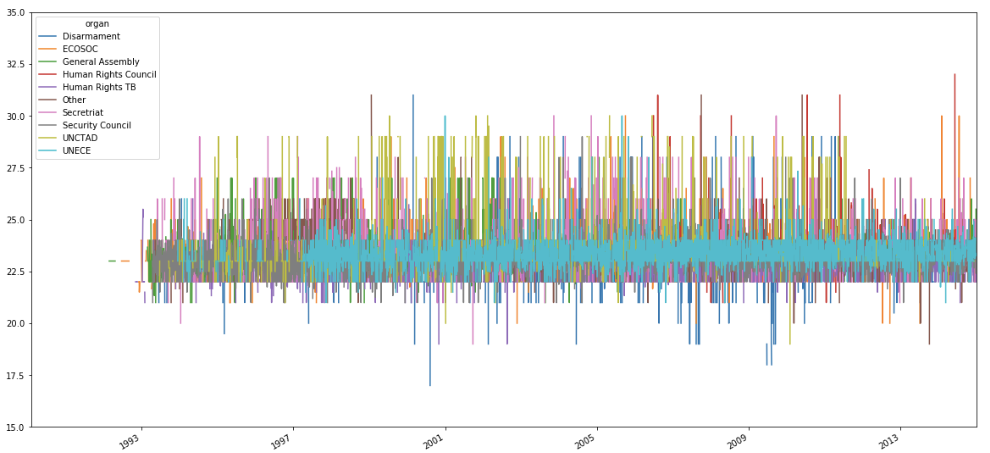
So I took the mean readability per quarter.

Most of the variations seem to have happened at the beginning. UNCTAD and Disarmament have some interesting variance during the early 2000s.
The number of documents per year in the data set is relatively constant.
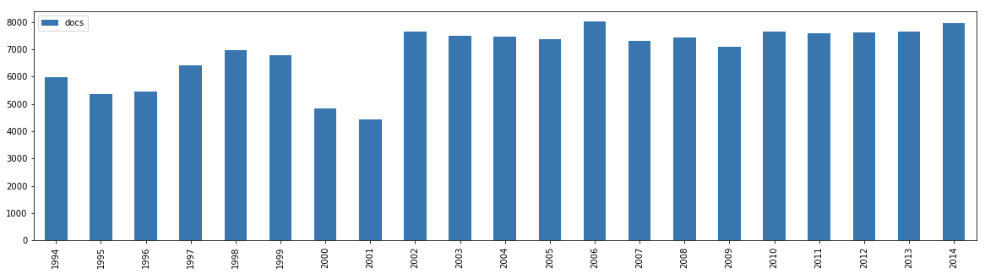
A plot of the number of documents per quarter helps us assess if the peaks and valleys in the scoring might be related to data-scarcity issues.

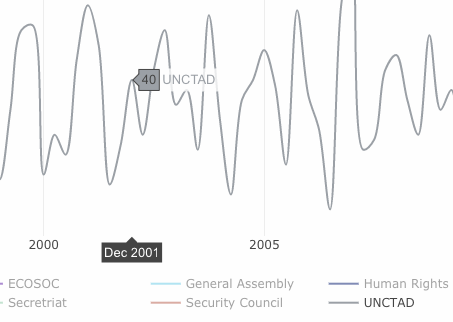
Going to the two specific examples, the UNCTAD Sep 2001–Mar 2002 period seems to have enough documents worth a deeper look. Not so much for Disarmament, with only 8 documents during its dip in June 2001.
By the way, nice seasonality on the General Assembly, ECOSOC, and Human Rights Council documents. These must be parliamentary documents that map neatly to their periodic sessions.
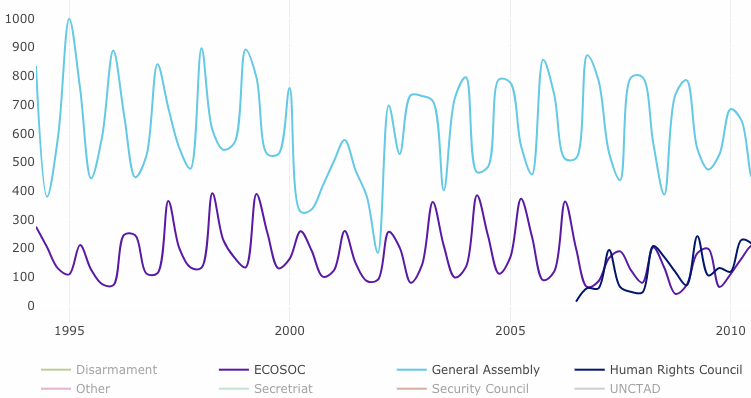
Looking at the tail end of the data, from around 2011 onwards, it seems that most of the scores have converged. This seems an interesting conclusion. Perhaps editing has become more systematic or streamlined?
How can this be improved
The UN corpus dataset that I used was English-only. Many of these texts had been already translated and even edited for readability. A more interesting study would be to analyze the readability of original submitted texts. This offers two complications: access to the original documents (this is almost impossible for texts submitted before the popularization of digital content management systems) and –more importantly– availability of readability formulae for languages other than English. Every formula I used have been modeled and tested for their applicability in English texts but I wasn’t able to find much information about comparable studies in other languages.
Checking against a dictionary of “easy” words has a fundamental flaw: it only checks against one variation of the word, doesn’t validate for plurals, gerunds, possessive forms, etc. One way to improve the current scoring would be to convert every word to their lemma before checking against the dictionary of easy words. This might even lower the minimum age for some text and introduce more interesting variances.
These documents are full of acronyms and agency names. Rarely more than 3 syllables long. A separate dictionary that classifies acronyms as “easy words” would help. Even better yet, use a trained Named Entity Recognizer that excludes names of organizations and places from the reading difficulty calculation.
The readability formulae have a lot of granularity between ages 5 and 17. The grading system seems to be designed for testing readability for primary education. If we had a similar kind of resolution from 24 to 40, a readability model for adults, we might be able to better classify these documents. This is more or less what editing tools like StyleWriter and Grammarly do. They measure against a larger dictionary of “easy” words, test for use of punctuation, passive voice and other criteria designed by professional editors. StyleWriter uses a proprietary “Bog Index” which includes eight additional criteria. It would be awesome if they provided a commercial API for it.
Speaking of APIs, the same experiments could be run against the following APIs to see if any of them report anything of interest:
- https://www.meaningcloud.com/developer/apis
- http://webknox.com/api#play
- http://www.hemingwayapp.com/
- https://www.perfecttense.com/developers#top
- https://www.gingersoftware.com/
- https://www.grammarbot.io/quickstart
Going back to the original premise, we could establish a comparison of readability for texts of similar length. Perhaps this could be a multi-tier system in which basic readability is calculated and then enriched with a set of more sophisticated APIs.
You can find the code for this project at https://github.com/danielpradilla/python-readability