
Westminster is one of the iconic fonts of the computer revolution. Probably its most famous use (apart from checks) is the Invisible Man video from Queen: … although arguably, that would be after its shelf life had expired. For me it was the Lode Runner (1983) font, which is burned in my retina. But Westminster… Continue reading Moore Computer
Daniel Pradilla
I'm an Engineer and my main objective is to help people solve real world problems using readily available technologies. I've been doing it since I was a kid.
Classification, visualized
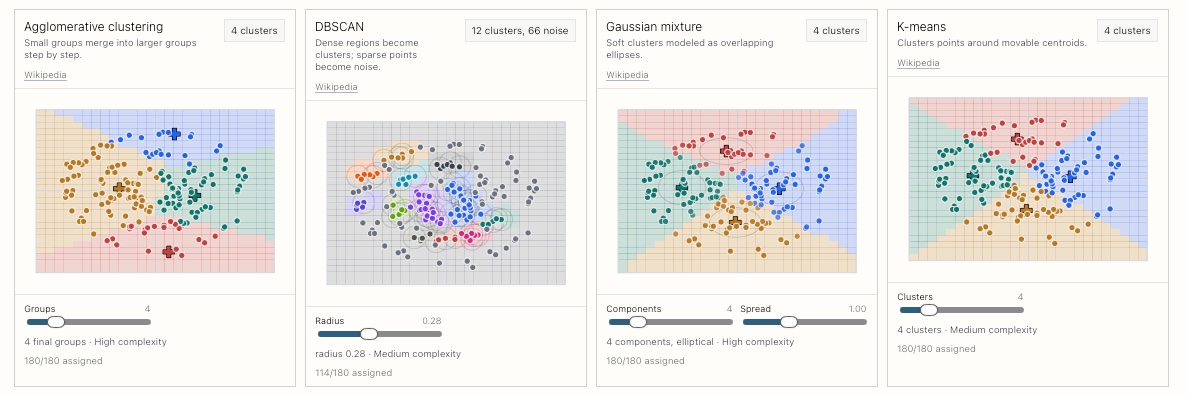
The other day, I was tinkering with model parameters and second-guessing myself. I wondered, wouldn’t it be cool if i could compare side by side the results of different models? Yeah, it would. I ended up building a small interactive explainer for seeing how different classification and clustering approaches behave on the same two-dimensional data.… Continue reading Classification, visualized
mambo-rescue

Rescuing an old website without turning it into a life project A few days ago, I finally got around to something I’d been putting off since about 2012: cleaning up a mess on one of my old websites. One part is still plain HTML. Another runs on WordPress. And in the middle, for a few… Continue reading mambo-rescue
Flipasio

My eldest daughter recently discovered the classic LCD calculator trick: type certain numbers, flip it, and make it spell words. She was thrilled to show me, and I was just as excited watching her find that little “useless” easter egg that entertained me during way too many hours in classes that I should’ve paid more… Continue reading Flipasio
EchoTree

For years now I kept some of my social accounts alive with a Python script. It read from a collection of RSS feeds and shared at random times. It worked, my feeds stayed active, and people asked me what was I doing reading at 3am. The script had a bit of personality: it logged out… Continue reading EchoTree